
会员动态丨双赛道第一,远鉴在Interspeech 2025上获多项荣誉
作者: 商会秘书处 时间: 2025-08-27 浏览量: 719
 远鉴三篇论文被大会录用发表,并在Multimodal Information Based Speech Processing (MISP) 2025 Challenge中脱颖而出,荣获赛道2(AVSR:音视频语音识别)和赛道3(AVDR:音视频分离与识别)双冠佳绩,并在会议期间完成口头报告。
远鉴三篇论文被大会录用发表,并在Multimodal Information Based Speech Processing (MISP) 2025 Challenge中脱颖而出,荣获赛道2(AVSR:音视频语音识别)和赛道3(AVDR:音视频分离与识别)双冠佳绩,并在会议期间完成口头报告。
 MISP 2025挑战赛作为Interspeech的重要赛事,聚焦多模态会议转录,旨在通过引入额外的模态信息(如视觉),推动语音处理技术的前沿发展。远鉴团队在音频及多模态领域持续深耕,入选论文围绕重叠语音自适应混合分离、语音情感识别、口吃语音识别与事件检测等关键技术展开创新研究。相关成果已深度集成于远鉴核心产品中。
MISP 2025挑战赛作为Interspeech的重要赛事,聚焦多模态会议转录,旨在通过引入额外的模态信息(如视觉),推动语音处理技术的前沿发展。远鉴团队在音频及多模态领域持续深耕,入选论文围绕重叠语音自适应混合分离、语音情感识别、口吃语音识别与事件检测等关键技术展开创新研究。相关成果已深度集成于远鉴核心产品中。
语音分离与ASR创新方案双突破
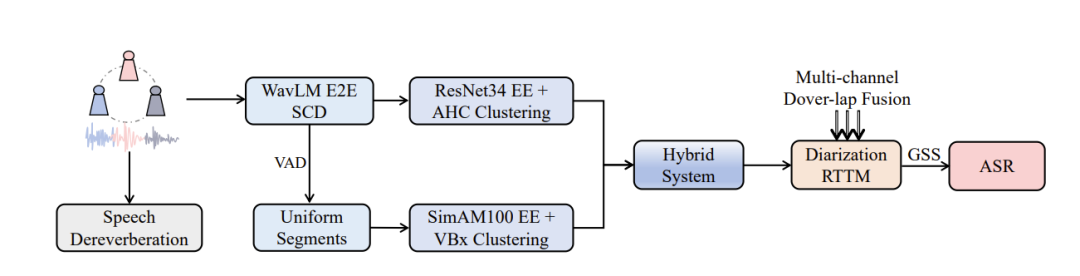
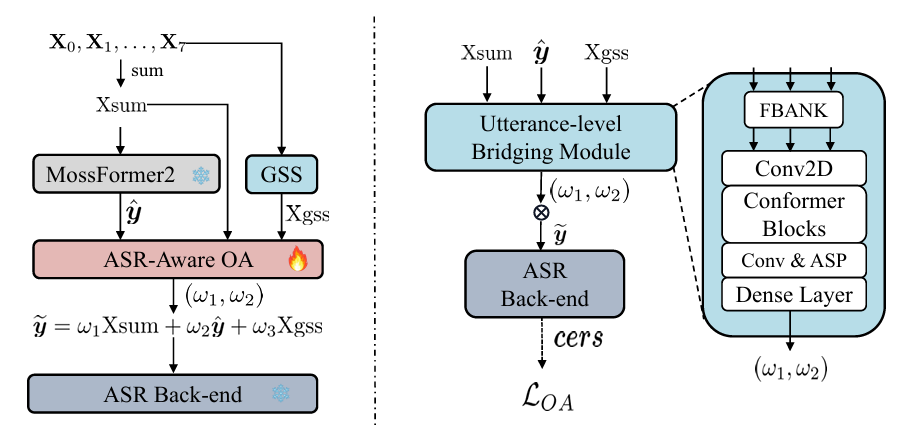
针对MISP 2025挑战赛,远鉴提出了一整套高效且创新的解决方案。在语音分离方面,采用结合WavLM端到端分割与传统多模块聚类的混合方法,能够自适应处理不同程度的语音重叠;在自动语音识别(ASR)方面,创新性地提出基于ASR感知的观察添加方法,有效弥补了低信噪比下引导源分离(GSS)的性能局限。通过以上提出的创新性方法,远鉴在赛道2和赛道3中均排名第一,充分彰显了该方案在真实会议场景下的卓越性能与技术领先优势。
解决自然场景语音情感识别挑战难题
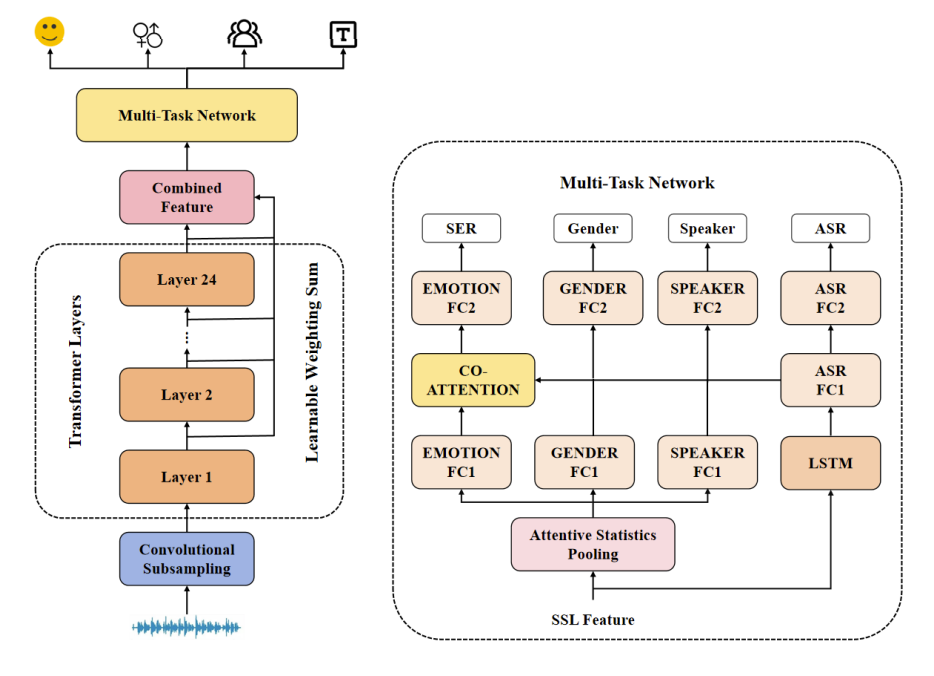
在处理语音情感识别任务时,远鉴针对自然场景语音情感识别场景提出了一种创新性解决方案。传统单任务模型在复杂环境下性能受限,而融合多任务学习与协同注意力机制的技术路径,展现出巨大的潜力。
远鉴所提出的多任务学习(MTL)方案结合了情感识别、性别分类、说话人验证和语音识别任务。该方案通过一种协作注意力机制,动态建模情感任务与辅助任务特征之间的交互,实现上下文感知的特征动态融合。此外,为应对少数类别样本识别困难以及语义相似样本难以区分的挑战,引入了一种加权焦点-对比学习损失函数,有效缓解了类别不平衡和语义混淆问题。
实验结果表明,远鉴所提出的方案显著提升了情感识别性能。
利用大语言模型应对口吃问题
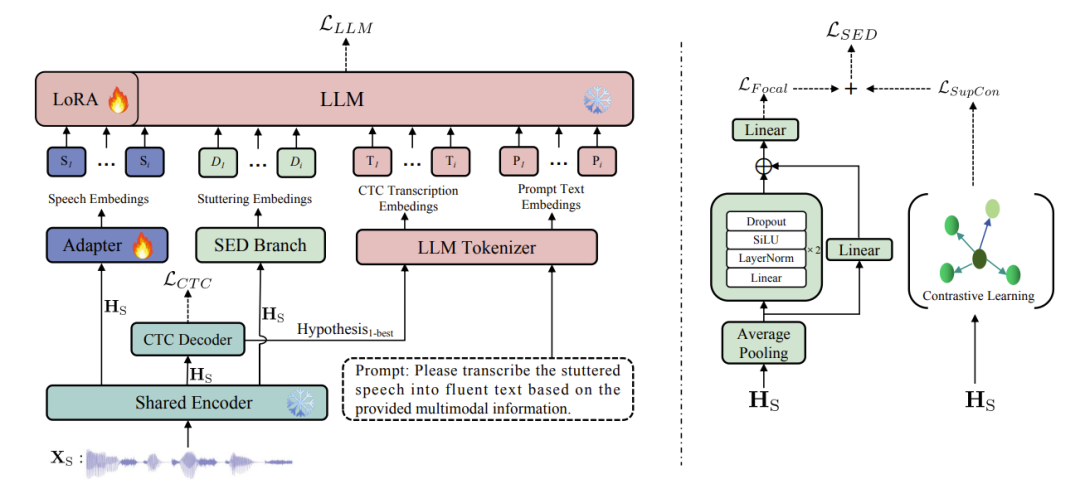
口吃是一种影响全球超8000万人的复杂神经发育障碍,其特有的言语重复、语音阻塞(阻塞音)和音节拖长(拖音)等症状,使得传统自动语音识别(ASR)技术在处理口吃语音时性能显著下降,严重制约了其在言语康复评估、辅助沟通等关键场景的应用。
针对这一长期存在的技术难题,我们提出了一种由大语言模型(LLM)驱动的ASR-SED多任务学习框架。该框架通过动态交互机制,利用ASR分支生成的CTC软提示来辅助LLM的上下文建模,同时通过SED分支输出口吃嵌入来增强LLM对口吃语音的理解。结合对比学习和Focal Loss的混合优化策略,该技术在普通话口吃语音场景下,成功实现了ASR与SED性能的双重突破,为言语康复等应用提供了坚实的技术支撑。
在权威的AS-70普通话口吃语音数据集上,远鉴取得了业界领先的性能表现。
远鉴在Interspeech 2025发表多篇论文,并在MISP 2025挑战赛上斩获双赛道第一,不仅是对公司科研实力的国际认可,更彰显了远鉴在语音技术前沿探索中的领先实力。未来,远鉴将持续深耕多模态语音处理技术,以创新为驱动,不断突破复杂场景下的语音理解与交互瓶颈,推动语音人工智能向更精准、更智能的方向发展。
(来源:远鉴信息技术有限公司公众号)